今回は複数のデータを管理する手法の一つである、セットについてお話ししていきます。
Pythonの魅力の一つはその豊富なデータ構造です。
その中でもセット(Set)は、重複を許さず順序のない要素の集まりを表現するための便利な手段です。本記事ではセットを活用するための基本的な操作に焦点を当て、初心者の方々に分かりやすく解説していきます。
またadd、remove、in、union、intersection、difference、issubset、issupersetなどのメソッドや操作について一つずつ見ていくことで、Pythonのセットを使った効果的なデータ管理がどれほど簡単かを体感できるでしょう。
動画もあるので一緒に活用してください。
Pythonにおけるセットの書き方
セットやタプルと同じように複数のデータを管理する書き方で、{ }で囲うとセットという種類になります。
test1 = {1,3,5,7,9}
test2 = {}
print(test1) # {1,3,5,7,9} {} と表示されるセットの書き方で特徴的なのがインデックス番号がないことです。
そのためリストやタプルのようにインデックス番号を使って特定の値を取得する書き方は使えません。
セットにおける要素の追加はaddメソッド、要素の削除はremoveメソッドを使います。
削除するときの指定方法はインデックス番号が使えないので「データの内容」を引数に渡します。
さらに「in」というキーワードを使って特定の要素がセットの中に存在しているか検索することもでき余す。
test1 = {1,3,5,7,9}
test1.add(11)
print(test1) # {1,3,5,7,9,11}と表示される
test1.remove(11)
print(test1) # {1,3,5,7,9}と表示される
print(1 in test1) # Trueと表示される
print(2 in test1) # Falseと表示されるセットの特徴の一つに重複削除の機能があります。
例えばaddメソッドを使って要素を追加する際に、元のセットにあるものをaddで追加しても自動的に重複削除されます。
こちらもインデックス番号という概念がないためです。
インデックス番号があれば値が重複していてもインデックス番号で棲み分けできるのが、セットではインデックス番号がないので自動的に同じ値は統一するようにしています。
test1 = {1,3,5,7,9}
test1.add(9)
print(test1) # {1,3,5,7,9}と表示されるIDのような重複したデータを作りたくない時に有効です。
Pythonでセットを使った論理計算
セットの特徴として論理計算、いわゆるベン図のようなことができる点が挙げられます。
まずは前章で紹介したように重複削除という機能がありますので結果的に和集合ができます。
unionメソッドを使うと2つのデータを合体させられるのですが、値が被っているものは一つにまとめられるケースです。
test1 = {1,2,3}
test2 = {4,5,6}
print(test1.union(test2)) # {1,2,3,4,5,6}と表示される
test3 = {2,4,6}
print(test1.union(test3)) # {1,2,3,4,6}と表示されるunionメソッドの他にintersectionメソッドというものを使うと「重複したものを知らせてくれる」ことができます。
これが数学的には積集合にあたるものです。
test1 = {1,2,3}
test2 = {4,5,6}
print(test1.intersection(test2)) # 重複はないので{1,2,3}と表示される
test3 = {2,4,6}
print(test1.intersection(test3)) # 2が重複しているので{2}と表示されるさらに積集合の反対の差集合はdifferenceメソッドというものでできます。
「重複していないものを知らせる」ということです・
test1 = {1,2,3}
test2 = {4,5,6}
print(test1.difference(test2)) # 重複はないので{1,2,3}と表示される
test3 = {2,4,6}
print(test1.difference(test3)) # 2が重複しているので{1,3}と表示される差集合と積集合は対になる考え方なので一緒に覚えておくと便利です。
ただ差集合についてはdifferenceメソッドを実行するセットで空のセットがセットが返ってくる点に注意です。
実行されたセットに存在していて、引数のセットには存在していないものはないからです。
「重複してない」だけしか頭にないと、differenceを実行するたびに思ったような結果にならないので違いを色んなパターンで試して理解しましょう。
test1 = {1,2,3}
test2 = {2}
print(test1.difference(test2))
# 実行されたセットに存在していて、引数のセットには存在していないものは1,3
print(test2.difference(test1))
# 実行されたセットに存在していて、引数のセットには存在していないものはない
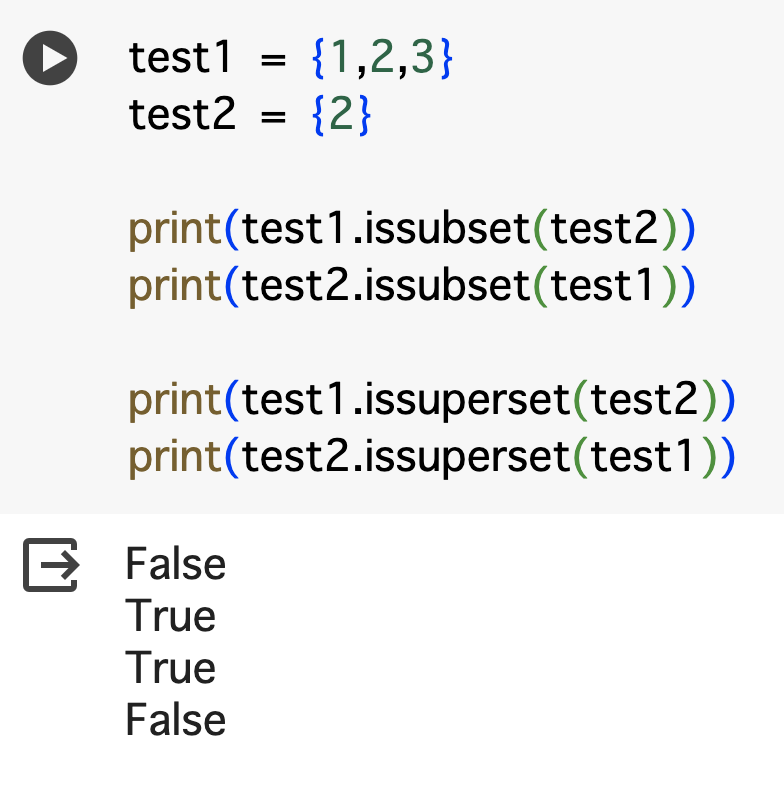
続いては部分集合と言われるものでissubsetメソッドを使うと「引数に含まれるか」、issupersetメソッドを使うと「引数を含んでいるか」をTrue ,Falseで判定できます。
test1 = {1,2,3}
test2 = {2}
# 引数のものが含まれているか判定
print(test1.issubset(test2))
print(test2.issubset(test1))
# 引数のものを含んでいるか判定
print(test1.issuperset(test2))
print(test2.issuperset(test1))