
今回はJSON形式のデータをPythonで処理する方法を解説していきます。
JSON形式のデータはAPIを中心にいろんな言語で使用されていますが、PythonではJSON形式という概念は定義されておらず、辞書型というデータに置き換えて考えます。
そのためJSONファイルをそのまま操作することができないので初心者のうちは戸惑いやすい部分でもあったりします。
本記事ではPythonの標準ライブラリであるjsonモジュールを使用して、以下のポイントに焦点を当てながらJSONファイルの読み書き方法を解説します。
・JSONファイルの読み込み方法(loads関数を使用)
・JSONファイルへのデータの書き込み方法(dumps関数を使用してファイルに書き込み)
・JSONファイルを読みやすく整形する方法(indentパラメータの使用)
また動画もあるので必要に応じて活用してください。
Pythonでjsonモジュールを使ってJSONファイルを使用する
まずはjsonモジュールというものが用意されているのでインポートします。
また仮のJSONデータを文字列で変数sampleとして用意します。
import json
sample = """
{
"id": "0001",
"name": "aaa",
"age": 21
}
"""通常の文字列は「””」ですがJSON形式は改行してインデントをずらすと見やすいので「”””」を使った文字列で表現しました。
現状はtypeメソッドでsampleをprintすると文字列として評価されます。
import json
sample = """
{
"id": "0001",
"name": "aaa",
"age": 21
}
"""
# ここを追加
print(type(sample)) # class strと表示される続いてjsonモジュールのloadsメソッドというものがあり、引数にJSONデータを入れると辞書型のデータに変換されます。
import json
sample = """
{
"id": "0001",
"name": "aaa",
"age": 21
}
"""
# ここを追加
dict_data = json.loads(sample)
print(dict_data, type(dict_data))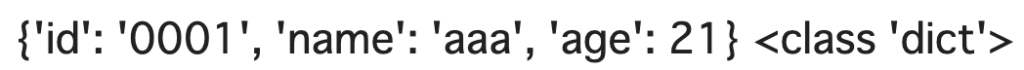
辞書になったのでキーを指定すれば値を取り出すことが可能になっています。
import json
sample = """
{
"id": "0001",
"name": "aaa",
"age": 21
}
"""
dict_data = json.loads(sample)
# ここを変更
print(dict_data["id"]) # 0001と表示される逆に再度JSON形式に戻すことも可能です。
その際にはjsonモジュールのdumpsというメソッドを使用して以下のように書きます。
import json
sample = """
{
"id": "0001",
"name": "aaa",
"age": 21
}
"""
dict_data = json.loads(sample)
# ここを追加
test_json = json.dumps(dict_data, indent=2, ensure_ascii=False)
print(type(test_json)) # class strと表示されるdumpsメソッドは第一引数に辞書型のデータを、第二引数にインデントの数を指定します。
indent=0にすると以下のようになります。

これでも良いのですが上記コードであったようにindent=2とすると以下のようになります。

第三引数のensure_ascii=Falseは日本語の文字化けを防ぐ効果があります。
任意ですが基本的には入れるものとしましょう。
Pythonでbs4モジュールを使ってHTMLをパースする方法
前章ではJSONファイルの変換でしたので続いてはHTMLファイルの変換を紹介します。
HTMLファイルの変換にはbs4というモジュールを使用します。
from bs4 import BeautifulSoup
html = "<html><body><p class='text'>テスト</p></body></html>"
soup = BeautifulSoup(html, "html5lib")
result = soup.find("p")
print(result) # 「テスト」と表示される今回はHTMLを手打ちで変数htmlとして用意しています。
BeautifulSoupというメソッドがあり、第一引数にHTMLデータを入れて第二引数にhtml5libという文字列を指定することでHTMLを解析できます。
BeautifulSoupメソッドの結果はHTMLがそのまま表示されます。

例えばpタグのみを取得したいときにはfind(“p”)とすることでpタグの中のテキストを取得できたわけです。
また取得したい要素が複数あって全て取得したいときにはfind_allメソッドを使用すると、引数に指定した要素がリスト形式になって取得できます。
あとはfor文で1件ずつ表示させるなどができるわけです。
from bs4 import BeautifulSoup
# ここを変更
html = "<html><body><p class='text'>テスト</p><p class='text'>テスト</p></body></html>"
soup = BeautifulSoup(html, "html5lib")
# ここを変更
result = soup.find_all("p")
print(result)
このようなbs4モジュールを使ったHTMLの変換はスクレイピングにも使用することができます。
サイトからHTMLファイルを取得するには事前にrequestsモジュールをインストールしておきます。
pip install requestsrequestsモジュールをインストールした上で、例えば「https://lorem-co-ltd.com」のHTMLファイルを解析したいときは以下のようにします。
import requests
from bs4 import BeautifulSoup
res = requests.get("https://lorem-co-ltd.com")
soup = BeautifulSoup(res.text, "html5lib")
p_tags = soup.find_all("p")
for p in p_tags:
print(p.text)requestsモジュールにはgetメソッドというものがあり、引数にサイトのURLを入れるとHTMLファイルを取得することができます。
そちらを先ほどのようにBeautifulSoupメソッドの引数に入れるわけです。
上記コードではpタグを全て取得していますので以下のような感じで出力されます。

ちなみにrequestsモジュールを使ったサイトURLをもとに情報を取得することをREST APIとも呼んだりします。
実はHTMLファイル以外にもいろんな情報が一緒に受け取れていて、例えばgetメソッドをそのまま中身を出力してみると以下のようになっています。
import requests
from bs4 import BeautifulSoup
res = requests.get("https://lorem-co-ltd.com")
print(res)
getメソッドを実行して得られる情報をレスポンスオブジェクトとも呼んだりします。
レスポンスオブジェクトの中にはいろんなプロパティがあり、その中の一部に先ほどのHTMLファイルが格納されていたということです。
HTMLファイル以外には以下のような情報を確認できます。
import requests
from bs4 import BeautifulSoup
res = requests.get("https://lorem-co-ltd.com")
# ここを変更
print(res.status_code) # 200と表示される
print(res.encoding) # UTF-8と表示される
print(res.headers) #↓のようなヘッダー情報が表示される
{'Server': 'nginx', 'Date': 'Mon, 26 Feb 2024 02:48:14 GMT', 'Content-Type': 'text/html; charset=UTF-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Vary': 'Accept-Encoding', 'Link': '<https://lorem-co-ltd.com/wp-json/>; rel="https://api.w.org/"', 'Content-Encoding': 'gzip'}REST APIでは情報の取得だけではなく情報の送信もできて、requestsモジュールでは以下のように書きます。
注意点としては投稿する場合にはURLが別で用意されていることが多いので、サイト閲覧時のURLではなく何のURLになるのか確認しましょう。
import requests
# 投稿データを辞書形式としてpayloadという変数に格納
payload = {"param": "test"}
requests.post("投稿先のURL", data=payload)また上記コードで送信データを変数payloadとしていますが、こちらのデータ形式をJSON形式で送信したい場合にはjsonモジュールをインポートしてdumpsメソッドを実行してrequests.postメソッドの第二引数に入れましょう。
import requests
# ここを追加
import json
# 投稿データをJSON形式としてpayloadという変数に格納
payload = {"param": "test"}
requests.post("投稿先のURL", json=json.dumps(payload))