

「書籍や学習教材でPandasという文字をよく見かけるけど何に使うものかイメージできない」
「シリーズやデータフレームといった新しいキーワードが何を指すのかイメージできない」
「データフレームを作成することはできるけど値の更新や操作まではやったことがない」
本日はそんな方に向けてPythonのPandasライブラリの使い方や頻出のメソッドを紹介します。
Python初心者がPandasをマスターする上で欠かせないのが、様々なデータ処理や解析を行うためのメソッドの理解です。
本記事ではPandasの基本的なメソッドであるSeriesやDataFrameの操作から、データの選択や操作、統計情報の取得、CSVファイルの読み込みといった幅広い機能をカバーします。
具体的には、locやiatを使ったデータの選択や変更、meanやmin、maxを使った統計情報の計算、そしてdescribeやreplace、read_csvなどを使ったデータの扱い方を丁寧に解説します。
Python初心者でも分かりやすく実践的な例を交えながら、Pandasの基本メソッドをしっかりと抑えてデータ処理のスキルを向上させていきましょう。
また動画もあるので必要な方は以下よりご覧ください。
PythonプロジェクトにPandasライブラリを導入してシリーズを作成する
Pandasはサードパーティ製のライブラリなのでインポート文だけでなくインストールの実行が必要です。
pip install pandasインストールが終了したらソースコード内でインポート文を書くことでPandas専用のメソッドやクラスを使用できるようになります。
import pandas以下のコードはSeriesと言って表形式の1列、いわゆる一次元のデータ配列を作成するものです。
第一引数に値をリスト形式にして、第二引数に行の識別をするための数字もしくは文字列を入れます。
import pandas
s = pandas.Series([1,2,3], index=["a","b","c"])
print(s)
#以下の結果になる
a 1
b 2
c 3インデックスが行番号、インデックス番号のような働きになるので、インデックスの名前を指定することで値の取得や更新ができます。
import pandas
s = pandas.Series([1,2,3], index=["a","b","c"])
print(s.a)
#以下の結果になる
1import pandas
s = pandas.Series([1,2,3], index=["a","b","c"])
s.a = 2
print(s)
#以下の結果になる
a 2
b 2
c 3Seriesが表形式の1列になるのですが、複数のSeriesがあると今度は表形式そのもの、つまり二次元の配列データになります。
Pandasでは二次元の配列データをDataFrameと呼びます。
import pandas
df = pandas.DataFrame([[1,2],[3,4],[5,6]], columns=["col1","col2"], index=[0,1,2])
print(df)
#以下の結果になる
col1 col2
0 1 2
1 3 4
2 5 6DataFrameというメソッドの第一引数に二次元のリストを入れて、第二引数であるcolumnsに列を識別する数字もしくは文字列、第三引数はSeriesと同じく行を識別するindexを指定します。
DataFrameは上記コードのように最初から作るのではなく、実務では辞書形式のデータをDataFrameに変換するというケースが多いです。
辞書をDataFrameの第一引数に入れると、自動的にcolumnsは省略できてindexのみを指定します。
import pandas
# 辞書からデータフレームを作る
dict = {"col1": [1,3,5], "col2": [2,4,6]}
df = pandas.DataFrame(dict, index=[0,1,2])
print(df)
#以下の結果になる
col1 col2
0 1 2
1 3 4
2 5 6PythonのPandasでデータフレームの値取得、更新のやり方
Pandasでは表形式のDataFrameという二次元配列のようなデータを扱えるようになります。
DataFrameを操作するための特別なメソッドがたくさんあり、統計によく使うメソッドを紹介します。
まずは辞書形式の変数dictをもとに変数dfという名前でデータフレームを作成しましょう。
import pandas
dict = {
"data": [100,200,300,400,500]
}
df = pandas.DataFrame(dict)
print(df)
#以下の結果になる
0 100
1 200
2 300
3 400
4 500この状態でいくつかメソッドを実行してみます。
import pandas
dict = {
"data": [100,200,300,400,500]
}
df = pandas.DataFrame(dict)
# 平均
print(df.mean()) #300となる
# データ件数
print(df.count()) #5となる
# 最大値、最小値
print(df.max(), df.min()) #500, 100となる
# ランダム
print(df.sample()) #100,200,300,400,500の中からランダムで選ばれた数字となるこのような数値計算や取得はPandasでなくても可能ですが、少々コードを書かなければなりません。
Pandasのデータフレームでは簡単なコードで実行できるので便利です。
また統計の主要数値はdescribeというメソッドで一括取得することも可能です。
import pandas
dict = {
"data": [100,200,300,400,500]
}
df = pandas.DataFrame(dict)
# 表示結果
count 5.000000
mean 300.000000
std 158.113883
min 100.000000
25% 200.000000
50% 300.000000
75% 400.000000
max 500.000000データフレームの中で1列だけ、1行だけ、1個だけ値を取得、更新する方法
続いて列単位、行単位で複数の値を一度に取得、更新する方法を紹介します。
import pandas
dict = {
"data": [100,200,300,400,500]
}
df = pandas.DataFrame(dict)
print(df)
#以下の結果になる
0 100
1 200
2 300まず列単位で取得するには列を識別するキーを指定します。
import pandas
dict = {
"data": [100,200,300,400,500]
}
df = pandas.DataFrame(dict)
print(df.aaa)
#以下の結果になる
aaa bbb
0 100 400
1 200 500
2 300 6001列はSeriesなので列単位の更新は以下のようにします。
import pandas
dict = {
"data": [100,200,300,400,500]
}
df = pandas.DataFrame(dict)
df.aaa = pandas.Series([101,102,103])
print(df)
#以下の結果になる
aaa bbb
0 101 400
1 102 500
2 103 600続いて行単位の値取得は以下のようにします。
import pandas
dict = {
"data": [100,200,300,400,500]
}
df = pandas.DataFrame(dict)
print(df.loc[0])
#以下の結果になる
aaa 100
bbb 400locというメソッドに行を識別する数字もしくは文字列を指定します。
また行単位の更新については「値が1個の列をn列作る」という意味になるので、列単位の更新と同じくSeriesを使います。
第一引数は更新内容で、n列という部分を認識するために第二引数に列を認識させる数字もしくは文字列を指定します。
import pandas
dict = {
"data": [100,200,300,400,500]
}
df = pandas.DataFrame(dict)
df.loc[0] = pandas.Series([101,102], index=["aaa","bbb"])
print(df)
#以下の結果になる
aaa bbb
0 101 102
1 200 500
2 300 600第一引数の更新内容は第二引数の列を識別するものと順番を揃えるのがルールです。
上記コードと違って以下のコードだと値が入る場所が変わりますので注意してください。
import pandas
dict = {
"data": [100,200,300,400,500]
}
df = pandas.DataFrame(dict)
#順番に注意
df.loc[0] = pandas.Series([101,102], index=["bbb","aaa"])
print(df)
#以下の結果になる
aaa bbb
0 102 101
1 200 500
2 300 600一方で単一の値を取得するにはiatというメソッドを使用して、エクセルのように[列、行]を指定します。
import pandas
dict = {
"data": [100,200,300,400,500]
}
df = pandas.DataFrame(dict)
print(df)
#以下の結果になる
aaa bbb
0 100 400
1 200 500
2 300 600
# 行と列を指定して取得
print(df.iat[0,1]) # 400になる
# 行と列を指定して更新
df.iat[0,1] = 101
#以下の結果になる
aaa bbb
0 100 101
1 200 500
2 300 600特定の条件を満たす値だけを取得するフィルタリング
続いて特定の条件を満たす値を取得するフィルタリングの方法を紹介します。
以下のようなデータフレームがあるとします。
import pandas
df= pandas.DataFrame({
"aaa":[100,200,300,400],
"bbb":[500,600,700,800]
})
print(df)
#以下の結果になる
aaa bbb
0 100 500
1 200 600
2 300 700
3 400 800こちらのデータフレームの値の中から「偶数行」を取得するには以下のようにします。
つまり前章のように1行だけではないということです。
import pandas
df= pandas.DataFrame({
"aaa":[100,200,300,400],
"bbb":[500,600,700,800]
})
pattern = (df.index % 2 == 0)
print(df[pattern])
#以下の結果になる
aaa bbb
0 100 500
2 300 700データフレーム[パターン]という書き方をすることで該当するパターンの行だけを取り出して、複数ある場合は全てを表示します。
ちなみにパターンの指定方法は以下のような書き方で表現することもあります。
リストのインデックス番号を見立てて偶数の位置をTrueにして奇数の位置をFalseにするものです。
import pandas
df= pandas.DataFrame({
"aaa":[100,200,300,400],
"bbb":[500,600,700,800]
})
# これでも同じ意味
pattern = [False, True, False, True]
print(df[pattern])
#以下の結果になる
aaa bbb
0 100 500
2 300 700またパターンではなく特定の値が含まれる行だけを取得するには以下のようにします。
以下の例では100がある行だけを取得しています。
import pandas
df= pandas.DataFrame({
"aaa":[100,200,300,400],
"bbb":[500,600,700,800]
})
# ここを変更
pattern = (df.aaa == 100)
print(df[pattern])
#以下の結果になる
aaa bbb
0 100 500「=」が使えるので他の不等号を使ったものでも可能です。
以下はaaa列の値で300をこえる値を含んだ行を取得しています。
import pandas
df= pandas.DataFrame({
"aaa":[100,200,300,400],
"bbb":[500,600,700,800]
})
# ここを変更
pattern = (df.aaa > 300)
print(df[pattern])
#以下の結果になる
aaa bbb
3 400 800不等号で「間」を取りたいときはパターンを2個作ってもOKです。
例えば以下の例ではaaa列の値で100より大きく400より小さい値を含んだ行を取得しています。
import pandas
df= pandas.DataFrame({
"aaa":[100,200,300,400],
"bbb":[500,600,700,800]
})
# ここを変更
pattern1 = (df.aaa > 100)
pattern2 = (df.aaa < 400)
pattern = pattern1 & pattern2
print(df[pattern])
#以下の結果になる
aaa bbb
1 200 600
2 300 700データフレーム同士で計算をさせる
値の取得、更新の他には異なるデータフレーム同士で計算をさせることも可能です。
以下のように2つのデータフレームを用意します。
import pandas
df1 = pandas.DataFrame({
"data": [100,200,300]
})
df2 = pandas.DataFrame({
"data": [400,500,600]
})
print(df1)
print(df2)
#以下の結果になる
data
0 100
1 200
2 300
data
0 400
1 500
2 600それぞれ1列のみのデータフレームかつ、列名が同じであれば以下のように演算子を使うことで実現できます。
import pandas
df1 = pandas.DataFrame({
"data": [100,200,300]
})
df2 = pandas.DataFrame({
"data": [400,500,600]
})
df = df1 + df2
print(df)
#以下の結果になる
data
0 500
1 700
2 900注意点としては列名が同じ場合にのみ計算ができるので以下のように違う列名のデータフレームはエラーになりませんが正常に計算ができません。
import pandas
df1 = pandas.DataFrame({
"test": [100,200,300]
})
df2 = pandas.DataFrame({
"data": [400,500,600]
})
df = df1 + df2
print(df)
#以下の結果になる
data test
0 NaN NaN
1 NaN NaN
2 NaN NaN計算以外だと置換という作業もデータフレームのなかで可能です。
以下のようにreplaceメソッドというものがあり、第一引数に変更前の値、第二引数に変更後の値を指定します。
import pandas
df = pandas.DataFrame({
"aaa": [100,200,300],
"bbb": [200,400,600]
})
df = df.replace(200, 201)
print(df)
#以下の結果になる
aaa bbb
0 100 201
1 201 400
2 300 600データフレームの値を昇順、降順にソート(並び替え)する方法
データを見やすくするためにソートをすることがあります。
例えば以下のようなデータフレームを用意します。
import pandas
data = {
"aaa": [1,2,3],
"bbb": [4,5,6],
"ccc": [7,8,9]
}
df = pandas.DataFrame(data, index=["a","b","c"])
print(df)
#以下の結果になる
aaa bbb ccc
a 1 4 7
b 2 5 8
c 3 6 9aaa列の数字を降順にしたいときにはsort_valuesというメソッドの第一引数に[aaa]と書いて、第二引数にascending=[False]とします。
import pandas
data = {
"aaa": [1,2,3],
"bbb": [4,5,6],
"ccc": [7,8,9]
}
df = pandas.DataFrame(data, index=["a","b","c"])
#ここを変更
print(df.sort_values(["aaa"],ascending=[False]))
#以下の結果になる
aaa bbb ccc
c 3 6 9
b 2 5 8
a 1 4 7逆に昇順にしたいときにはsort_valuesの第二引数をascending=[True]とします。
import pandas
data = {
"aaa": [1,2,3],
"bbb": [4,5,6],
"ccc": [7,8,9]
}
df = pandas.DataFrame(data, index=["a","b","c"])
#ここを変更
print(df.sort_values(["aaa"],ascending=[True]))
#以下の結果になる
aaa bbb ccc
a 1 4 7
b 2 5 8
c 3 6 9エクセルと同じように特定の列をソートすると他の列も並び変わります。
数字の他には英語のアルファベット順にソートすることも可能です。
データフレームの中にあるデータの不備(欠損値)を確認、削除する方法
データというのはユーザーからの入力や自然情報の観測など自分たちでコントロールできない状況で収集することが多いです。
何かの間違いで一部データの不備が混じることがあり、先ほどのソートなど不備があると上手く操作できないことに繋がります。
そのためデータの不備を確認、もしくは削除することが必要でpandasでは専用のメソッドが用意されています。
例えば以下のようにbbb列にNoneという値があるとします。
data = {
"aaa": [1,2,3],
"bbb": [4,None,6]
}
print(data)
#以下の結果になる
aaa bbb
0 1 4.0
1 2 NaN
2 3 6.0そのような不備を示す結果を確認するにはisnullというメソッドを使用することで、不備があればTrueを返します。
data = {
"aaa": [1,2,3],
"bbb": [4,None,6]
}
print(data)
# 欠損値の有無を判定
print(pandas.isnull(df.aaa).any())
print(pandas.isnull(df.bbb).any())
#以下の結果になる
False
Trueaaa列についてはFalseになり、bbb列については不備があるのでTrueになりましたね。
また確認した上で不備の行を削除するにはdropnaというメソッドを使用します。
data = {
"aaa": [1,2,3],
"bbb": [4,None,6]
}
print(data)
# 欠損値の除去
new_df = df.dropna()
print(new_df)
#以下の結果になる
aaa bbb
0 1 4.0
2 3 6.0いつでも綺麗なデータを収集できるとは限りませんので、初心者の方も欠損値の確認や削除は使用できるようになっておきましょう。
データフレームからCSVに変換する方法
データフレームは表形式のデータであることからCSVのように見えますが、厳密には違うものですのでCSVとして表計算ソフトに入れたいときには変換が必要です。
まず以下のようなCSVがあるとき読み込みにはread_csvを使います。
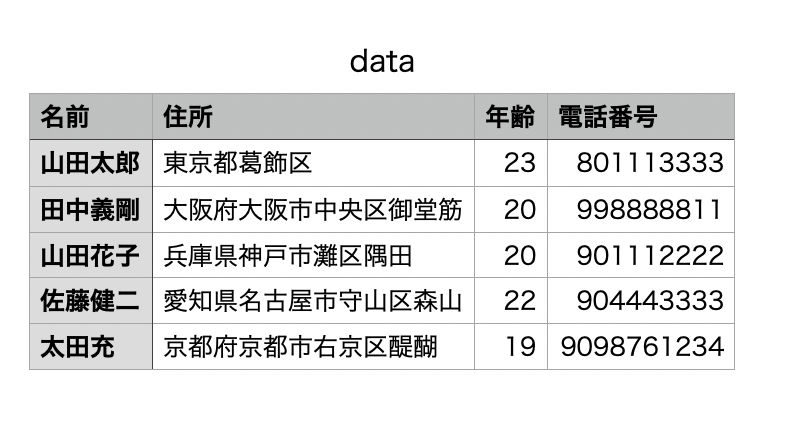
import pandas
df = pandas.read_csv("/content/data.csv")
print(df)
#以下の結果になる
名前 住所 年齢 電話番号
0 山田太郎 東京都葛飾区 23 801113333
1 田中義剛 大阪府大阪市中央区御堂筋 20 998888811
2 山田花子 兵庫県神戸市灘区隅田 20 901112222
3 佐藤健二 愛知県名古屋市守山区森山 22 904443333
4 太田充 京都府京都市右京区醍醐 19 9098761234続いて辞書からデータフレームに変換しておきます。
import pandas
# 辞書からデータフレームを作ってCSVに出力する
dict = {"col1": [1,3,5], "col2": [2,4,6]}
df = pandas.DataFrame(dict, index=[0,1,2])
print(df)
#以下の結果になる
col1 col2
0 1 2
1 3 4
2 5 6変数dfをCSV形式のファイルとして出力するにはto_csvメソッドを使用することでパソコンに落とすことができます。
import pandas
# 辞書からデータフレームを作ってCSVに出力する
dict = {"col1": [1,3,5], "col2": [2,4,6]}
df = pandas.DataFrame(dict, index=[0,1,2])
print(df)
# ここを追加
df.to_csv("output.csv", index=False)CSVの読み込み、書き出しは頻出の作業なので初心者の方も練習しておきましょう。