

「TypeScriptってよく聞くけどJavaScriptより難しそうで勉強するのが億劫に感じている」
「求人でよく見かけるTypeScriptって何のために使われているのかよくわからない」
「typeとinterfaceの違いがよくわからず勉強している」
今回はWeb制作やJavaScriptで開発をしている方に向けて、TypeScriptの基本を解説していこうと思います。
初めてTypeScriptを学ぶ方にとっては、型の書き方やその使い方に戸惑うこともあるかもしれません。
本記事ではTypeScriptを使ううえで最低限知っておきたい、型の書き方に絞ってついて説明します。
データに型を書くルールや、”type”や”interface”といった基本的な型の定義方法、”extends”や”extra”といった型の拡張方法、さらにはジェネリクス(T)の活用方法までを紹介します。
専門用語が登場しますが何かしらJavaScriptで開発をしたことがある方ならすぐにキャッチアップできる内容です。
また動画でも解説しているので必要に応じて活用してください。
TypeScriptにおける型の書き方と考え方
TypeScriptで型を指定して変数を宣言する
TypeScritpはあくまでJavaScriptの文法にデータの「型」を書くだけのものです。
「型」とはデータの種類のようなもので、文字、数字、配列などのことです。
例えば以下のように書きます。
// 文字列の変数を宣言している
let str: string = "hello";
// 数字の変数を宣言している
let num: number = 18;名前の右側に「:」をつけて型名を書きます。
型名については文字列はstringで数字はnumberのように決まったキーワードがあるのですが、事前に暗記しておくというよりは実際に開発をやりながら1個ずつ覚えていくのが良いでしょう。
ちなみに型は「〇〇 | ▲▲」と書いて「〇〇もしくは▲▲の型」のように複数で書くこともできます。
TypeScriptでは「ユニオン型」という言い方をします。
// 文字列もしくは数字の変数を宣言して、初期値を文字列にした
let memberId: string | number = "0001";
// 後から数字を代入している
memberId = 12;外部APIの取得など事前に型が不明な場合や、後から改修する見込みがある場合などに使うことがありますので覚えておきましょう。
TypeScriptで配列に型を指定する
続いて配列、オブジェクトのように複数のデータを扱う場合の書き方です。
配列の場合だと以下のように書きます。
// 文字列の要素の配列を宣言している
let arr: string[] = ["aaa", "bbb", "ccc"];このように複数のデータを扱う場合には中身の要素に対しての型も考えることになりますので注意してください。
また配列にも複数の型を指定することができます。
// 文字列もしくは数字の要素の配列を宣言している
let arr: (string | number)[] = ["aaa", "bbb", "ccc"];配列の要素のインデックス番号順に型指定をする方法もあり、こちらだと順番通りの型で要素が並んでいないとエラーになります。
// 数字、文字列、文字列の順番の配列
let arr: [number, string, string] = [100, "aaa", "bbb"];
// 0番目に数字以外のデータを代入することができない
arr4[0] = "bbb"; // エラー
arr4[0] = 200; // [200, "aaa", "bbb"]になるさらに配列にはJavaScriptのメソッドが使えますが、メソッドに渡す引数の型が合わないとメソッドはエラーになります。
// 文字列の要素の配列を宣言している
let arr: string[] = ["aaa", "bbb", "ccc"];
// 数字を追加しようとする
arr.push(1);
ちなみに処理の仕様で「空の配列を先に宣言する」というケースがあります。
配列は要素の型を指定するわけなので、空の配列は自動的にany型になります。
そのため空の配列を宣言する場合にも「最終的にどんなデータを格納する予定か?」を考えて先に型指定することが多いです。
// 空の配列はany型になるが型指定を書く
let arr: number[] = [];
arr.push("aaa"); // エラーになる
arr.push(100); [100]になる初学者の方はエラーと聞くと怖い印象を持たれるかもしれませんが、逆に言うと「事前に間違いを教えてくれる」ということです。
TypeScriptを使う大きな動機がエラーを減らすことです。
そのためエラーになることは悪いことではなく、それだけミスを防いでくれていると考えてみましょう。
TypeScriptでオブジェクトに型を指定する
続いて配列と同じようにオブジェクトについても同様の書き方と考え方になります。
オブジェクトにも中身のプロパティについても型を考えていきます。
// それぞれのプロパティの型を指定してオブジェクトを宣言している
let obj: {
id: string;
name: string;
age: number;
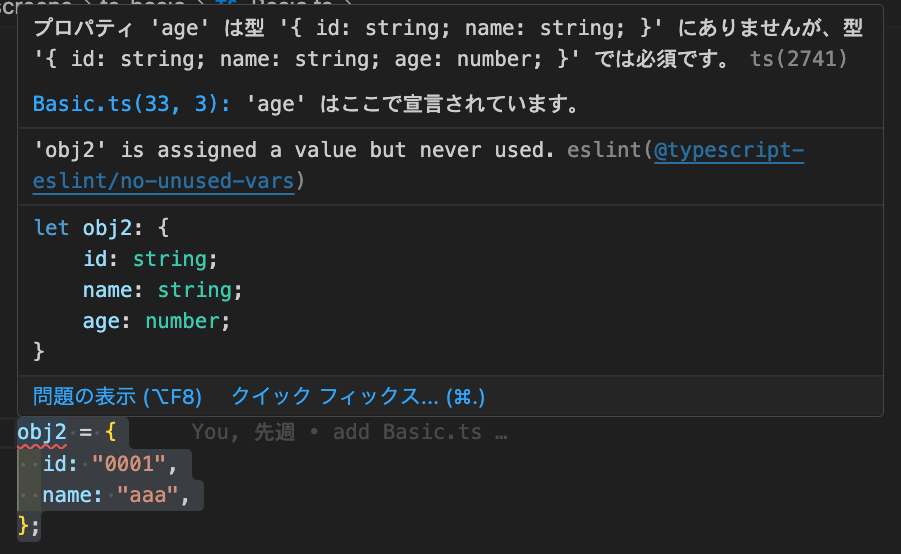
};オブジェクトで注意しないといけないのが、宣言したプロパティは過不足なく使用することです。
どう言うことかと言うと3つのプロパティを宣言したのに2つのプロパティしか使用しないと警告になります。
// それぞれのプロパティの型を指定してオブジェクトを宣言している
let obj: {
id: string;
name: string;
age: number;
};
// ageを使わなかった
obj = {
id: "0001",
name: "aaa",
};
とはいえ実際の開発ではプロパティの必要性をすべて把握できるわけではありません。
その場合はJavaScriptのオプショナルチェーンを使用できます。
// それぞれのプロパティの型を指定してオブジェクトを宣言している
// ageは任意項目にしている
let obj: {
id: string;
name: string;
age?: number;
};
// ageを使わなくても大丈夫
obj = {
id: "0001",
name: "aaa",
};いわゆる必須か任意かを選ぶことができるわけですね。
「?」をつけることをJavaScriptで学んでこなかった方は一度以下の動画をご確認ください。
TypeScriptで関数の引数と戻り値に型を指定する
関数については引数と戻り値についての型を指定することになります。
以下は文字列の引数と数字の引数(任意)によって文字列の戻り値を出す関数になります。
引数もオブジェクト同様に任意項目にすることがあり、こちらもオプショナルチェーンを使用できます。
// 関数はデフォルトでは引数と戻り値に型を指定する
const func1 = (str: string, num?: number): string => {
console.log(str);
return "bbb";
};
func1("aaa");関数の戻り値については処理内容によって不要な場合があります。
戻り値のない関数についてはvoidという型を戻り値に指定します。
// 関数の戻り値ではvoidという型があり、戻り値を不要とするもの
const func2 = (str: string): void => {
console.log(str);
};
func2("aaa");TypeScriptで登場するtypeとinterfaceの使い方
TypeScriptではデータに型を指定するものだと説明してきました。
ここまでのお話が理解できれば開発に進んでも大丈夫なのですが、チーム開発では効率的に開発を行うためのルールがあります。
同じような型指定は変数のように何かのキーワードを書くだけで使い回せると作業が楽です。
プログラミングの世界では「エイリアス」とも呼ばれていて、TypeScriptではtypeとinterfaceがエイリアスの役割を持った文法です。
typeとinterfaceという型の書き方を説明していきますので、就職を考えている方はそれぞれマスターしておきましょう。
TypeScriptでtypeを使った型ルールを作る
まずtypeを使うことで型指定のルールを事前に作ることができます。
TypeScriptでは型を指定するわけですが、同じようなデータに何回もデータの指定をするのは実務では大変な作業になります。
そういった場合に繰り返し使いそうなデータには事前に型のルール(ひな型)を書くことで少々効率的な書き方ができるようになります。
例えば以下のような関数を書くとします。
const func4 = (name: string, num?: number) => {
console.log(name, num);
};
func4("aaa");関数の引数は「文字列と数字(任意)」という型ですが、この組み合わせの引数は他の関数を作る時にも発生しそうな組み合わせです。
そのような場合に以下のように書くことができます。
type argType = {
name: string;
num?: number;
};
const func5 = (arg: argType) => {
console.log(arg.name, arg?.num);
};argTypeという名前で「文字列と数字(任意)」という組み合わせを事前に書くことで、同じ組み合わせの引数を使うときには「arg: argType」と書けばOKになります。
注意としてはtypeの時点で「num?: number」のように任意(オプショナルチェーン)がある場合、そのtypeを利用するときにも「arg?.num」のようにオプショナルチェーンで書くことです。
type argType = {
name: string;
num?: number;
};
const func5 = (arg: argType) => {
// numは任意項目のため関数など実行する際にもオプショナルチェーンでの実行になる
console.log(arg.name, arg?.num);
};上記コードのように関数の引数にtypeを使用する場合、「この引数はパターン化できそうか?」という感覚は経験値がいるので初学者には難しく感じるかもしれませんがtypeの書き方は覚えておきましょう。
またtypeを使った関数を作った場合、その関数を実行するときは以下のように引数を指定します。
type argType = {
name: string;
num?: number;
};
const func5 = (arg: argType) => {
console.log(arg.name, arg?.num);
};
// 関数の引数はオブジェクトで準備したため、関数の実行時の書き方の変更には初学者は注意
func5({ name: "aaa" });通常の関数の引数の代入とは違う書き方ですよね、初学者の方は関数の実行までセットで書き方を覚えるようにしてください。
さらに引数だけではなく関数の作りまでパターン化することも可能です。
以下は「文字列と数字(任意)で戻り値はない関数」というものです。
引数と戻り値をパターン化した場合は関数名に「:」をつなげてtype名を書くので引数には型を書かなくて良くなります。
type initFunc = (first: string, second?: number) => void;
const func3: initFunc = (name, num) => {
console.log(name, num);
};
func3("aaa");関数のほかにオブジェクトについてもtypeを使った型指定をよく使います。
オブジェクトはプロパティの数が多いと毎回それぞれの型を書くのが大変ですよね。
// typeを使わずにオブジェクトを宣言する書き方
let obj1: { id: string; name: string; age: number } = {
id: "0002",
name: "bbb",
age: 21,
};
// typeを使った場合の書き方
type sample = {
id: string;
name: string;
age: number;
sports: string[];
};
// 同じプロパティの構成であればtype名だけ書けばOK
let obj2: sample = {
id: "0003",
name: "ccc",
age: 22,
sports: ["baseball", "soccer"],
};TypeScriptにおけるinterfaceの使い方
typeと同じようにパターン化する目的で使用するinterfaceというものもあります。
最近のトレンドとしてはinterfaceを使うことが多いのと、typeと若干書き方が違うのでしっかり練習しておきましょう。
// タイプと似たようなものでインターフェースもある、タイプと若干書き方が違うため初学者は注意
type argType = {
name: string;
num?: number;
};
interface ArgInterFace {
id: string;
name: string;
age: number;
}interfaceにはtypeには無い特徴的な使い方があります。
まずはパターンの継承ができることです。
「パターンに追加で〇〇がある型」のような時に使うことができます。
interface ArgInterFace {
id: string;
name: string;
age: number;
}
// ArgInterFaceのパターンを引き継いだ新しいUserというパターンを作った
interface User extends ArgInterFace {
address: string;
}
// こちらはArgInterFaceを利用した
const test1: ArgInterFace = {
id: "0001",
name: "aaa",
age: 20,
};
// Userを型定義に利用する場合はaddressが無いとダメ
const test2: User = {
id: "0002",
name: "bbb",
age: 21,
address: "tokyo",
};事前にArgInterFaceという3つのプロパティをパターン化したものを用意していましたが、急遽4つ目のプロパティを追加することになった例です。
もう1個新しいパターンを書き直しても良いですが、interfaceでは継承することで「ルールを書き足す」ことができます。
注意点として「上書き」では無いので、ArgInterFaceとUserは別物であることを認識しておく必要があります。
継承しても元のArgInterFaceは残り続けるわけです。
TypeScriptにおける「T」ジェネリクス
さらに継承の進んだ使い方でextraというものがあります。
継承だけでも便利ですが、ルールを書き足すことを繰り返すと何回も継承することになります。
例としてブログサイトを開発しているとします。
ブログ記事のデータをオブジェクトとして扱うことになり、id(ユニークID)とtitle(記事タイトル)とdesc(記事本文)の3つのプロパティを使うことになりました。
しかし後から記事ごとにカテゴリーとタグも追加したくなったときは継承ではなくextraというもので以下のような書き方ができます。
// 項目の有無が不明確だったり何回も継承する場合はextraが使える
interface Category {
category: string;
}
interface Tag {
tag: string;
}
interface ArgMore<T> {
id: string;
title: string;
desc: string;
extra: T[];
}
// 基本情報にカテゴリーを追加したいとき
const blog1: ArgMore<Category> = {
id: "0001",
title: "title1",
desc: "desc1",
extra: [{ category: "category1" }],
};
// 基本情報にタグを追加したいとき
const blog2: ArgMore<Tag> = {
id: "0001",
title: "title1",
desc: "desc1",
extra: [{ tag: "tag1" }],
};基本のArgMoreというパターンにおいてextraというプロパティを書くことで、extraには任意で追加プロパティを追加することができるようになります。
上記の例ではblog1という記事にはカテゴリーを追加、blog2という記事にはタグを追加しています。
もちろん先ほどの継承でも同じことができますが、「何が来るかわからない」「何回も継承することになりそう」という場面ではextraの方が良いとされています。
またextra: T[ ];となっているようにextraは配列なので複数の追加もできるようになっています。
Tについては「ここには何か別のinterfaceの名前が入りますよ」という目印です。
blog3という記事にカテゴリーとタグを追加するには以下のようにします。
interface Category {
category: string;
}
interface Tag {
tag: string;
}
interface ArgMore<T> {
id: string;
title: string;
desc: string;
extra: T[];
}
// 基本情報にカテゴリーとタグを追加したいとき
const blog3: ArgMore<Category & Tag> = {
id: "0001",
title: "title1",
desc: "desc1",
extra: [{ category: "category1" },{ tag: "tag1" }],
};extraで使っている「T」という記号は「ジェネリクス」とも呼ばれます。
必ず使うものではないですが初心者の方も存在だけは頭に入れておくと他人のコードを読みやすくなります。
よくある例としては外部APIからデータを取得するケースです。
初めて使う外部APIだと何がどんな形式で返ってくるかわからないことが多いですよね。
以下のような配列が返ってきたデータだとします。
const arr = [1, 2, 3];返ってきた配列の最初の要素だけを取得する関数を作ってみます。
const arr = [1, 2, 3];
const first = getFirst(arr);
console.log(first); // 1が表示される
function getFirst(arr: number[]) {
return arr[0];
}ただユーザーが入力した内容によっては数字が文字列としてAPIに入っていることもあります。
そのような場合だと上記のコードではコンパイルエラーになります。
// ここを変更
const arr = ['1', '2', '3'];
const first = getFirst(arr);
console.log(first); // 型が違うため取得できない
function getFirst(arr: number[]) {
return arr[0];
}純粋な数字型か文字列で作られた数字かどちらが来るかわからないとき、一番シンプルなのは関数getFirtstをユニオン型で作成しておくことでしょう。
const arr = ['1', '2', '3'];
const first = getFirst(arr);
console.log(first); // エラーを回避できる
// ここを変更
function getFirst(arr: (number | string)[]) {
return arr[0];
}同じような解決方法として使えるのがジェネリクスという「T」の記号です。
エイリアスとしてapiTypeを作成して配列データの部分をdataプロパティにして値をTにします。
// ここを追加
type apiType<T> = {
data: T;
isError: boolean;
};
const arr = ['1', '2', '3'];
const first = getFirst(arr);
console.log(first);
function getFirst(arr: (number | string)[]) {
return arr[0];
}前章のextraでも触れたようにTと書いた部分は汎用的に操作することが可能な値になります。
またTを使ったときはエイリアス名に<T>と書き足すのもルールです。
続いて関数getFirstの引数にエイリアスapiTypeを追加します。
type apiType<T> = {
data: T;
isError: boolean;
};
const arr = ['1', '2', '3'];
const first = getFirst(arr);
console.log(first);
// ここを変更
function getFirst<T>(arr: T[]) {
return arr[0];
}ユニオン型は明確に「文字列か数値のどちらか」という指定になりますが、ジェネリクスは「何かしら」というもっと抽象的な仕組みです。
結果的に同じくエラー回避になるわけですが、このようなケースでジェネリクスが使えたりします。
ジェネリクスは抽象的で自由度が高いのでエイリアス自体を引数のように変えてしまうことも可能です。
エイリアスapiTypeはAPIから返ってくるデータを想定したものですので、同じAPIでクエリを変えて別データを取得する際にも再利用することができます。
type apiType<T> = {
data: T;
isError: boolean;
};例えば学生情報を取得する際にapiTypeを利用して以下のように使うことができます。
type apiType<T> = {
data: T;
isError: boolean;
};
// ここから追加
type studentType = apiType<{ id: string; name: string; age: number }>;
const student: studentType = {
data: {
id: '0001',
name: 'aaa',
age: 20,
},
isError: false,
};
console.log(student);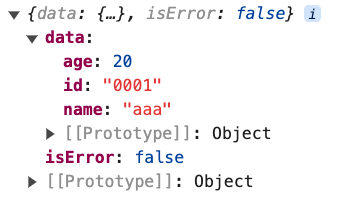
dataに先ほどまでの数字ではなくオブジェクト型で学生情報が格納されたとして、apiTypeのdataはTで自由になっているので後からプロパティごとの型ルールを追加したstudentTypeというエイリアスの作成に利用できます。
ポイントとしてはTは任意でいろんな型を入れるので拡張や再利用がしやすく別々のエイリアスを共存させやすいことです。
上記の状態から今度はブログのデータが返ってきたとしたら以下のように書き足すことになります。
type apiType<T> = {
data: T;
isError: boolean;
};
type studentType = apiType<{ id: string; name: string; age: number }>;
const student: studentType = {
data: {
id: '0001',
name: 'aaa',
age: 20,
},
isError: false,
};
console.log(student);
// ここから追加
type articleType = apiType<{ id: string; title: string; desc: string }>;
const article: articleType = {
data: {
id: '0001',
title: 'タイトル',
desc: '本文です',
},
isError: false,
};
console.log(article);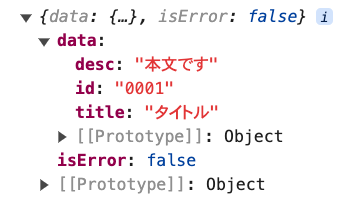
自由すぎるのでバグの温床になることもありますが、ジェネリクスを使うとエイリアスを効率的に書いたり後から修正しやすくなります。
最近ではTypeScript自体の性能が向上していてジェネリクスを使用しなくても同じようなことができるようになっていて、ジェネリクスの使用頻度は下がってきていますがオープンソースなど他人のコードをみて「Tって何?」とならないように覚えておきましょう。
typeとinterfaceの使い分けや初心者が勘違いしやすい書き方の違い
エイリアスというものを使うと型定義に汎用性や効率性を持たせることがわかりました。
初心者の方では「typeとinterfaceってどっちの方が良いの?」と思われたかもしれません。
結論、どちらも正解なので仕様に合わせて使い分けることが必要です。
そこで改めてそれぞれの書き方の違いや使い分けについて紹介しておきます。
初心者の方は必ず勘違いしていることなので押さえておきましょう。
typeには={ }で、interfaceは{ }で書く
非常にややこしいですがtypeは変数のように=で繋げてオブジェクト形式にしますが、interfaceは=で結ぶことができません。
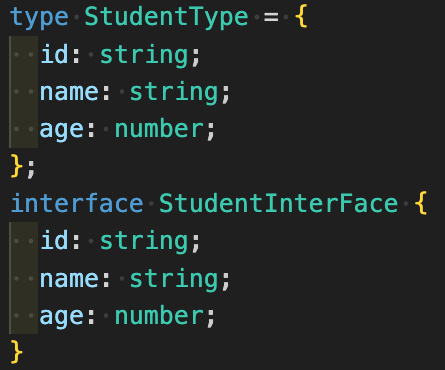
interfaceで間違って=を書くとコンパイルエラーになりますので注意しましょう。
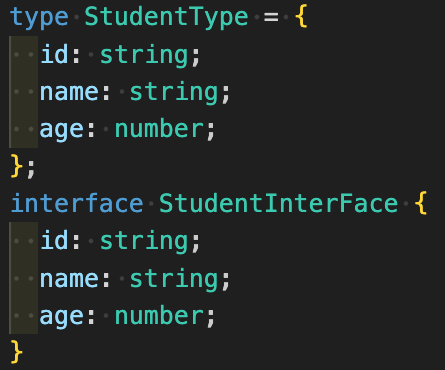
初心者の方が一番間違いやすいのがエイリアスにしたい対象が単一のデータのときです。
typeだとデータが単一だと=で結んで1行で書けるのですがinterfaceはオブジェクト形式にする必要があります。

こちらも1行で書けると感覚的に思ってしまうのでinterfaceに=を入れてコンパイルエラーになりがちです。

そのため単一のデータをエイリアスにするときはtypeが好ましいとされています。
拡張するときtypeは&を使って、interfaceはextendsを使う
続いてエイリアス同士を合体させたいなどの拡張時の違いです。
例えばすでにあるエイリアスと定義内容が一部同じなので、合体させた上で新しいルールを作りたいとします。
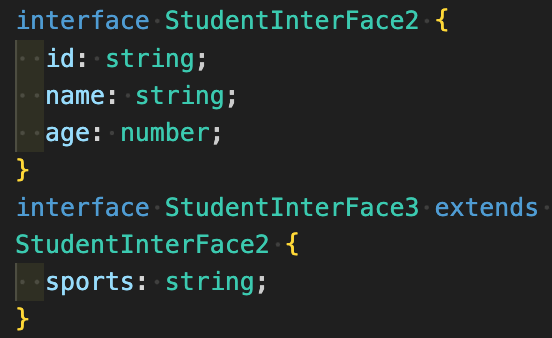
typeは条件分岐のように&を使うのに対して、interfaceはextendsを使います。
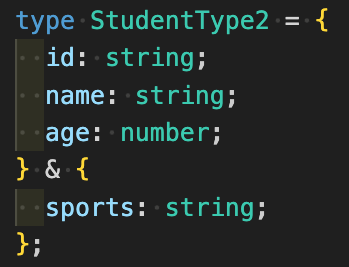
初心者の方はtypeの方が直感的に使いやすいかもしれませんね。
interfaceだと新しく作るエイリアスに名前を作る必要があります。
ちなみにですがinterfaceのみ同じエイリアスを2回書いて上書きすることで拡張することも可能です。

注意としては上書きになるので、他の場所ですでにid, name, ageの3種類だけの型定義を使っている場合には、sportsが追加されることで「sportsが追加されたのにsportsのデータがないですよ」というエラーになる可能性があります。
typeについては&無しで同じ名前でエイリアスを作ることはコンパイルエラーで最初から出来ない仕様になっています。
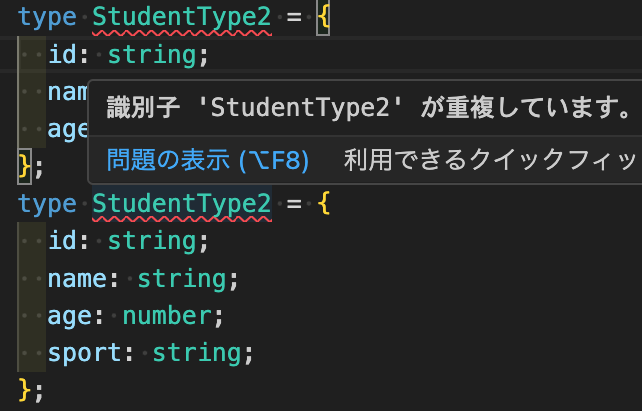
interfaceのみ同じ名前で上書きできますが実務としては好まれない書き方ですので初心者の方は知識として持っておく程度にすると良いでしょう。
エイリアス拡張によるinの使い方
型定義やエイリアスについてググっていると時折「in」を使って書き方を見ることがあると思うので解説しておきます。
こちらはオブジェクトに特定のプロパティが存在するかをtrue,falseで判定するものでJavaScriptの文法になります。
そもそもは違う目的で存在していたのですがTypeScriptのエイリアスと組み合わせると便利な使い方ができるので使う人が一定数います。
例えば以下のような2種類のエイリアスがありemailプロパティの有無で「顧客」「スタッフ」を分けているものとします。
// 顧客のエイリアス
type Person = {
id: string;
name: string;
};
// スタッフのエイリアス
type Staff = Person & {
email: string;
};システムの画面にアクセスしたユーザーが顧客かスタッフかを条件分岐で見分けて別々の処理をしたいときは以下のように書くことができます。
if ('email' in test) {
console.log('スタッフです。');
} else {
console.log('顧客です。');
}手書きでユーザーデータを作って試してみましょう。
type Person = {
id: string;
name: string;
};
type Staff = Person & {
email: string;
};
const user: (Person | Staff)[] = [
{
id: '0001',
name: 'aaa',
},
{
id: '0002',
name: 'bbb',
email: 'test@test.com',
},
{
id: '0003',
name: 'ccc',
email: 'test@test.com',
},
];
const test = user[0];
console.log(test);
if ('email' in test) {
console.log('スタッフです。');
} else {
console.log('顧客です。');
}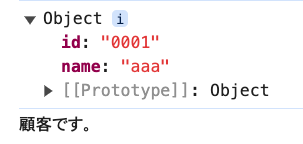
0番目のデータはemailを持っていませんので「顧客」と判定しました。
1番目のデータを選択してみましょう。
type Person = {
id: string;
name: string;
};
type Staff = Person & {
email: string;
};
const user: (Person | Staff)[] = [
{
id: '0001',
name: 'aaa',
},
{
id: '0002',
name: 'bbb',
email: 'test@test.com',
},
{
id: '0003',
name: 'ccc',
email: 'test@test.com',
},
];
// ここを変更
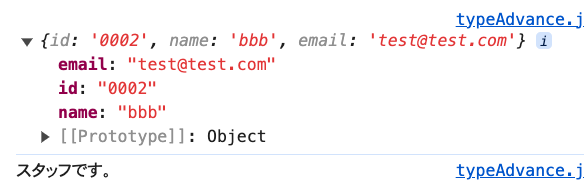
const test = user[1];
console.log(test);
if ('email' in test) {
console.log('スタッフです。');
} else {
console.log('顧客です。');
}
asを使った型アサーションで上書きする
TypeScriptによる型推論やすでに設定した型について、変数の代入のように後から上書きすることができて「アサーション」と呼んだりします。
type Type1 = string;
type Type2 = string | number;
let test1: Type1 = 'hello';
let test2 = test1 as Type2;上記コードではstring型の変数test1を別の変数であるtest2に代入しています。
そのため変数test2についても型推論よりstring型が自動で設定されるわけですが、あえて文字列もしくは数字というstring | numberを当てたい時に「as」に繋げて型名もしくは上記コードのようにtype名を指定することで上書きできます。
二つの変数は両方とも「hello」という文字列が格納されているにも関わらず、変数test1はstring型ですが、変数test2はstring | numberにすることができています。
もう少し複雑な例でも見ていきましょう。
const addOrConcat = (
a: number,
b: number,
c: 'add' | 'concat'
): number | string => {
if (c === 'add') {
return a + b;
} else {
return '' + a + b;
}
};
const concatResult: string = addOrConcat(1, 2, 'concat');
console.log(concatResult);上記の関数は第三引数が「add」であれば第一引数と第二引数を足し算して、第三引数が「concat」であれば第一引数と第二引数を文字列として結合するものです。
第一引数と第二引数は何かしら数字が入るので型推論で定数concatResultは数値型になります。
そのため上記コードのように定数concatResultにstringを指定しようとするとコンパイルエラーになります。

関数addOrConcatの戻り値ではstring | numberと指定していても、上記のように別の定数に代入する時には関数の戻り値の型指定は無視されるからです。
そんな時に型アサーションを使って文字列を指定するわけです。
const addOrConcat = (
a: number,
b: number,
c: 'add' | 'concat'
): number | string => {
if (c === 'add') {
return a + b;
} else {
return '' + a + b;
}
};
// ここを変更
const concatResult: string = addOrConcat(1, 2, 'concat') as string;
console.log(concatResult);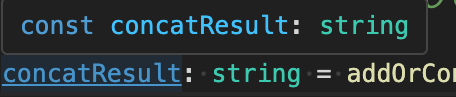
定数concatResultが強制的にstring型になりましたね。
型アサーションはHTMLのDOM操作でも使用できます。
以下のようなHTMLがあるとします。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<script src="./js/type-casting.js" defer></script>
</head>
<body>
<div class="container"></div>
<div id="wrapper"></div>
</body>
</html>divタグが2つありますね、例えばDOMの取得するときに書き方によって型推論が変わります。
const div = document.querySelector('div');
const container = document.querySelector('.container') as HTMLDivElement;両方ともdivタグを取得できるのですがタグでざっくり指定するのか属性名で限定的に取得するのかの違いです。
上記のようにHTML要素はいろんな取得ができますので型推論で正確に推測されることは少なく、多くの場合は以下のようにElement | nullというざっくり推論になります。

divタグだからHTMLDIVElementに推論してくれると思っていたら気をつけてください。
そこでアサーションを使って推論し切れてないコードに対して「これはdivタグを取得しています」という意味で上書きするわけです。
const div = document.querySelector('div');
// ここを変更
const container = document.querySelector('.container') as HTMLDivElement;Element | nullだとnullの可能性があるので条件分岐が必要になりますが、自ら型指定を上書きすることでnullの可能性を潰して条件分岐を省略することにも繋がります。
TypeScriptでインデックス型を使った自由度の高い型指定を使用する
TypeScriptは型を限定することで保守性を上げる一方で、ジェネリクスやオプショナル型のような少しの緩さを許容することができることを説明してきました。
そんな中、ほぼJavaScriptと同じくらいにまで許容範囲を広げて自由度をあげる方法があります。
インデックス型と呼ばれていて「型指定の値はもちろん、キーが決まっていなくてもOK」というものです。
interfaceによる型指定を例にしてみます。
インデックス型は[index: 型種類]というプロパティの書き方をします。
interface SStudent {
[index: string]: string | number;
id: string;
name: string;
age: number;
}
const student1: Student = {
id: '0001',
name: 'yamada',
age: 20,
};定数student1にはidとname,ageの3種類のプロパティがありますが、新しい4つ目のプロパティを入れることができます。
ジェネリクスやオプショナル型でも同じようなことはできますが、interfaceで型指定する時点で「プロパティ名」だけは決めておく必要があり、値の有無を任意にするものでした。
インデックス型は値だけでなくプロパティ自体も任意にできるのです。
例えば上記コードでinterfaceにない「test」という4つ目のプロパティを追加してもコンパイルエラーになりません。
interface SStudent {
[index: string]: string | number;
id: string;
name: string;
age: number;
}
const student1: Student = {
id: '0001',
name: 'yamada',
age: 20,
};
// 新しいプロパティと値を追加
student1['test'] = "tanaka";
console.log(student1); // {id: '0001', name: 'yamada', age: 20, test: 'tanaka'}新しく追加したプロパティの値はinterfaceで許容した型種類のみで再代入も可能です。
interface SStudent {
[index: string]: string | number;
id: string;
name: string;
age: number;
}
const student1: Student = {
id: '0001',
name: 'yamada',
age: 20,
};
student1['test'] = "tanaka";
// 再代入
student1['test'] = "yoshida";
console.log(student1); // {id: '0001', name: 'yamada', age: 20, test: 'yoshida'}ほとんどJavaScriptのような緩さですね。
そこでインデックス型は「readonly」というキーワードを追加することで、新しく追加できる任意のプロパティについて「新規作成のみで再代入は不可」にすることができます。
interface SStudent {
// ここを変更
readonly [index: string]: string | number;
id: string;
name: string;
age: number;
}
const student1: Student = {
id: '0001',
name: 'yamada',
age: 20,
};
student1['test'] = "tanaka";
// 再代入
student1['test'] = "yoshida";
// id, name, ageでないインデックス型は再代入不可のためコンパイルエラーになる「必須項目はプロパティ名を限定して再代入可能、任意項目はプロパティ名は自由で再代入不可」といったような細かい要件に対応させることができるわけです。
ちょっとしたテクニックの組み合わせで便利な管理ができますので試してみましょう。
typeやinterfaceなど専門用語が登場しますが、書き方はJavaScriptの基本であるオブジェクトや配列なので書いていくうちに慣れてくると思います。
今まで型を意識したことがないプログラムから1段上のレベルに行くためにTypeScriptも練習しておきましょう。